MySQL Logical Architecture
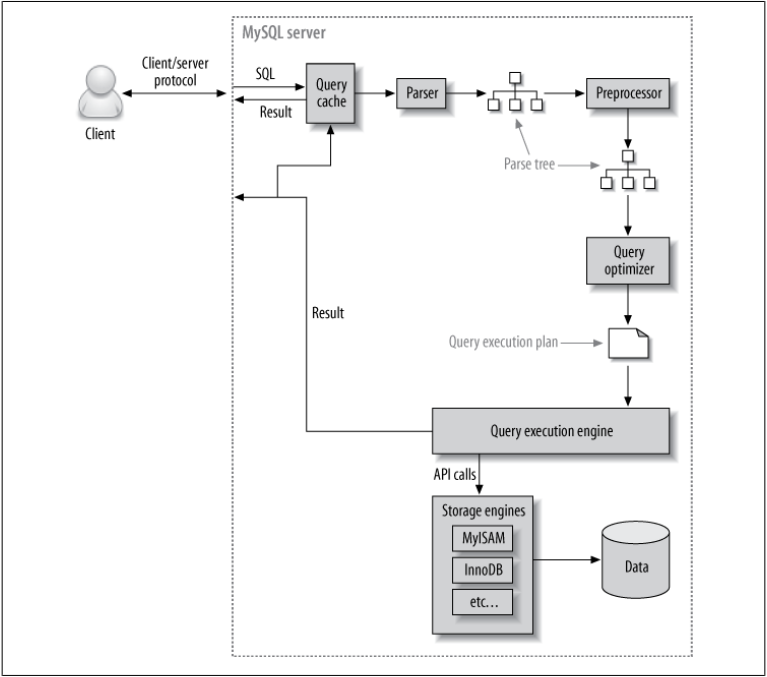
Internal working of mysql.

Top Layer i.e client are not unique to mysql. In client-server model we require connection handling, authentication, security which is provided by network based tools.
Second Layer i.e server is the brain of MYSQL it includes Query Parsing, analysis, optimisation, caching, and all the built-in functions (e.g., dates, times, math, and encryption). Any functionality provided across storage engines lives at this level: stored procedures, triggers, and views, for example.
Third Layer i.e storage engines, they are responsible of storing and retrieving all data stored in mysql. MyISAM and InnoDB are commonly used storage engines. MySql server communicates with storage engine through API’s.
What happens when you send MySQL a query?
- The client sends the SQL statement to the server.
- The server checks the query cache. If there’s a hit, it returns the stored result from the cache; otherwise, it passes the SQL statement to the next step.
- The server parses, preprocesses, and optimizes the SQL into a query execution plan.
- The query execution engine executes the plan by making calls to the storage engine API.
- The server sends the result to the client.
Connection Management and Security
Each client connection gets its own thread within the server process. The connection’s queries execute within that single thread, which in turn resides on one core or CPU. The server caches threads, so they don’t need to be created and destroyed for each new connection.
MySQL 5.5 and newer versions support an API that can accept thread-pooling plugins, so a small pool of threads can service many connections.
Optimisation and Execution
MySQL parses queries to create an internal structure (the parse tree), and then applies a variety of optimizations. These can include rewriting the query, determining the order in which it will read tables, choosing which indexes to use, and so on. You can pass hints to the optimizer through special keywords in the query, affecting its decision making process. You can also ask the server to explain various aspects of optimization. This lets you know what decisions the server is making and gives you a reference point for reworking queries, schemas, and settings to make everything run as efficiently as possible.
The optimizer does not really care what storage engine a particular table uses, but the storage engine does affect how the server optimizes the query. The optimizer asks the storage engine about some of its capabilities and the cost of certain operations, and for statistics on the table data.
Before even parsing the query, MySQL server checks into the query cache, which can store only SELECT statements, along with their result sets. If a query is identical to one already in the cache, the server doesn’t need to parse, optimize, or execute the query at all — it can simply pass back the stored result set.

The MySQL Client/Server Protocol
The protocol is half duplex, that means at any given time the MySQL server can be either sending or receiving messages, but not both.
The client sends a query to the server as a single packet of data. This is why the max_allowed_packet configuration variable is important if you have large queries. Once the client sends the query, it doesn’t have the ball anymore; it can only wait for results. (If the query is too large, the server will refuse to receive any more data and throw an error), On the other hand response from the server usually consists of many packets of data. When the server responds, the client has to receive the entire result set that is why LIMIT plays a important role. When a client fetches rows from the server, it thinks it’s pulling them. But the truth is, the MySQL server is pushing the rows as it generates them. The client is only receiving the pushed rows; there is no way for it to tell the server to stop sending rows.
The Query Cache
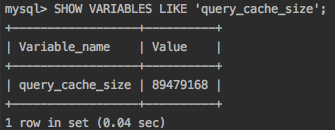
As discussed earlier, before even parsing query MySQL server checks into the query cache if result is found it is directly returned without even parsing, optimizing, or executing the query. MySQL allocates and initializes the specified amount of memory for the query cache all at once when the server starts from a value assigned to variable ‘query_cache_size’. If you update this variable (even if you set it to its current value), MySQL immediately deletes all cached queries, resizes the cache to the specified size, and reinitializes the cache’s memory. This can take a long time and stalls the server until it completes, because MySQL deletes all of the cached queries one by one, not instantaneously.
The Query Optimization Process
MySQL turns a SQL query into an execution plan for the query execution engine. It has several substeps: parsing, preprocessing, and optimization. Errors (for example, syntax errors) can be raised at any point in the process.
The parser and the preprocessor
MySQL’s parser breaks the query into tokens and builds a “parse tree” from them. The parser uses MySQL’s SQL grammar to interpret and validate the query. For instance, it ensures that the tokens in the query are valid and in the proper order, and it checks for mistakes such as quoted strings that aren’t terminated. The preprocessor then checks the resulting parse tree for additional semantics that the parser can’t resolve. For example, it checks that tables and columns exist, and it resolves names and aliases to ensure that column references aren’t ambiguous. Next, the preprocessor checks privileges. This is normally very fast unless your server has large numbers of privileges.
The query optimizer
The parse tree is now valid and ready for the optimizer to turn it into a query execution plan. A query can often be executed many different ways and produce the same result. The optimizer’s job is to find the best option.
MySQL uses a cost-based optimizer, which means it tries to predict the cost of various execution plans and choose the least expensive. The unit of cost was originally a single random 4 KB data page read, but it has become more sophisticated and now includes factors such as the estimated cost of executing a WHERE clause comparison. You can see how expensive the optimizer estimated a query to be by running the query, then inspecting the Last_query_cost session variable:
SHOW STATUS LIKE ‘Last_query_cost’;
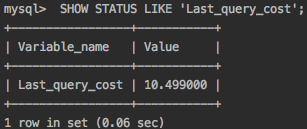
This result means that the optimizer estimated it would need to do about 10 random data page reads to execute the query. It is based on various factors such as number of pages per table or index the cardinality (number of distinct values) of the indexes, the length of the rows and keys, and the key distribution. The optimizer does not include the effects of any type of caching in its estimates — it assumes every read will result in a disk I/O operation.
The optimizer might not always choose the best plan, for many reasons:
• The statistics could be wrong. The server relies on storage engines to provide statistics, and they can range from exactly correct to wildly inaccurate. For example, the InnoDB storage engine doesn’t maintain accurate statistics about the number of rows in a table because of its MVCC architecture.
• The cost metric is not exactly equivalent to the true cost of running the query, so even when the statistics are accurate, the query might be more or less expensive than MySQL’s approximation. A plan that reads more pages might actually be cheaper in some cases, such as when the reads are sequential so the disk I/O is faster, or when the pages are already cached in memory. MySQL also doesn’t understand which pages are in memory and which pages are on disk, so it doesn’t really know how much I/O the query will cause.
• MySQL’s idea of “optimal” might not match yours. You probably want the fastest execution time, but MySQL doesn’t really try to make queries fast; it tries to minimize their cost, and as we’ve seen, determining cost is not an exact science.
•MySQL doesn’t consider other queries that are running concurrently, which can affect how quickly the query runs.
• MySQL doesn’t always do cost-based optimization. Sometimes it just follows the rules, such as “if there’s a full-text MATCH() clause, use a FULLTEXT index if one exists.” It will do this even when it would be faster to use a different index and a non-FULLTEXT query with a WHERE clause.
• The optimizer doesn’t take into account the cost of operations not under its control, such as executing stored functions or user-defined functions.
Concluding the optimizer — can’t always estimate every possible execution plan, so it might miss an optimal plan.
Optimizer can’t always estimate every possible execution plan, so it might miss an optimal plan.
The execution plan
MySQL doesn’t generate byte-code to execute a query, as many other database products do. Instead, the query execution plan is actually a tree of instructions that the query execution engine follows to produce the query results.
The final plan contains enough information to reconstruct the original query.
If you execute EXPLAIN EXTENDED(query) on a query, followed by SHOW WARNINGS, you’ll see the reconstructed query (The server generates the output from the execution plan. It thus has the same semantics as the original query, but not necessarily the same text).
The Query Execution Engine
MySQL simply follows the instructions given in the query execution plan. To execute the query, the server just repeats the instructions until there are no more rows to examine. Query execution engine communicates with storage engine through API call’s. Functions performed by the query execution are:
- It acts as a dispatcher for all commands in the execution plan.
- It iterates through all the commands in the plan until the batch is complete And it interacts with the storage engine to retrieve and update data from tables and indexes.
MySQL’s Storage Engines
MySQL stores each database (also called a schema) as a subdirectory of its data directory in the underlying filesystem. When you create a table, MySQL stores the table definition in a .frm file with the same name as the table. Thus, when you create a table named MyTable, MySQL stores the table definition in MyTable.frm. Because MySQL uses the filesystem to store database names and table definitions, case sensitivity depends on the platform. You can use the SHOW TABLE STATUS command to display information about tables.
Returning Results to the Client
The final step in executing a query is to reply to the client. Even queries that don’t return a result set still reply to the client connection with information about the query, such as how many rows it affected.
If the query is cacheable, MySQL will also place the results into the query cache at this stage. The server generates and sends results incrementally. As soon as MySQL processes the last table and generates one row successfully, it can and should send that row to the client.
This has two benefits: it lets the server avoid holding the row in memory, and it means the client starts getting the results as soon as possible.
************************* THANK YOU ***************************
For more details refer High Performance MySQL book by Baron Schwartz, Peter Zaitsev, and Vadim Tkachenko.
